

语音识别控制智能小车-deepcar
具体安装方法是:由于deepcar内部的usb口已经被体积较大的intel movidius神经网络计算棒占据,所以无法预装进去,需要在小车断电状态下先把deepcar的前挡板先拆掉,然后将神经网络计算棒取下,将usb声卡插上, 然后打开无线麦克风收发模块的开关,如果蓝灯闪烁则没有配对,如果蓝灯不闪,则说明收发模块已经配对成功。将无线麦克风的接收端插入到usb声卡的音频输入口(注意usb声卡有两个口,一个是音频输入口,一个是音频输出口,不要搞错,否则小车无法接收到声音),然后将前挡板安回,打开小车电源。

通过命令行窗口使用ssh登陆到deepcar,后执行如下命令:
cd deepcar/launch
roslaunch start_local_speech.launch
启动后控制台打印信息
对着无线麦克风的发送模块说英文指令可以控制小车的前进、后退、左转、右转、加速和减速,同时控制台上会打印相应的识别出来的指令,对于的指令分别是:
前进:move
后退:go bcak
左转:turn left
右转:turn right
加速:speed up
减速:slow down
高级例程-在线语音对话和控制
注意:语音识别需要先安装好usb声卡和无线麦克风
在前面一个例子中我们演示了离线的语音控制,但是由于树莓派的计算资源有限,所以只能完成简单的控制指令的识别,如果需要更复杂的语音任务,例如类似智能音箱的语音对话,则需要借助在线的语音识别API。
所谓开源的语音识别API,即网上现有的调用接口,开发工程师可利用这个接口完成需要的业务。在这个案例中,我们需要完成的业务就是将语音数据转化为文字,那么我们在网上选好一个语音识别API后,将数据传输过去即可。整个流程调用流程如下:我们利用输入设备,通过说话后获取了一段音频,然后将音频作为数据传输到语音识别API接口,之后像我们点击了一个网页链接一样,它会返回给你语音识别结果。
上述整个过程也叫做云服务。它利用互联网传输数据的便利和高配置计算机的算力优势,可让我们直接跳过开发离线模型,部署模型等步骤,快速将原始数据转化为我们需要的结果。目前国内各大互联网公司,如百度、腾讯、科大讯飞等,都开放了他们的语音识别API接口,供开发者调用。
目前市面上的智能音箱也是同样原理,利用云服务平台的在线语音识别接口来实现语音对话,这节我们来将deepcar变成一个类似小米“小爱”一样的智能音箱。
和本地语音识别一样,在线语音识别也需要安装好usb声卡和无线麦克风,具体步骤参照前面本地语音识别的步骤。
安装完成后启动小车,通过命令行窗口使用ssh登陆到deepcar,后执行如下命令:
cd deepcar/launch
roslaunch start_online_speech.launch
启动后控制台打印信息如图17所示
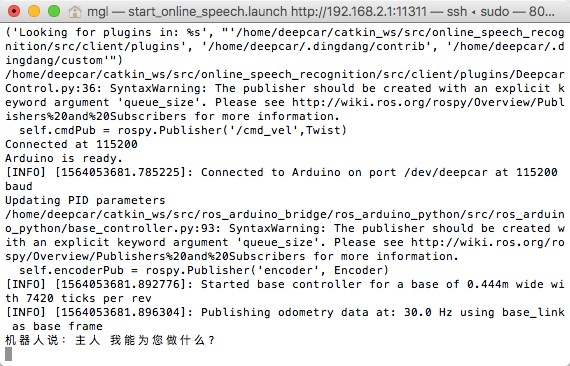
和智能音箱类似,对deepcar启动语音对话时需要先唤醒deepcar,唤醒词是heycar或者heydeepcar,对着小车说heydeepcar,deepcar在识别到唤醒词后会发出“滴”的一声,然后就可以对着小车说话了,例如说:“你叫什么名字”,说完后如果一秒内检测不到声音,则deepcar认为说话结束,会发出“滴”的一声表明说话结束,然后将采集到声音发送到百度的在线语音识别接口,得到识别结果,并将结果处理,返回相应的回答指令。
除了和deepcar对话外,还可以用语音来控制deepcar的动作,比如说:前进一米,则deepcar会自动前进一米然后停下,“右转90度“,deepcar会原地向右旋转90度然后停下。还可以对deepcar说:播放音乐,则deepcar自动登录到网页云音乐播放音乐,这些功能都是以插件的形式开发的,用户可以使用python开发更多的功能,比如使用语音来查询天气、控制deepcar的关机等。
 添加微信咨询
添加微信咨询